 使用NVIDIA GPU加速Apache Spark中Parquet数据扫描
使用NVIDIA GPU加速Apache Spark中Parquet数据扫描

随着各行各业的企业数据规模不断增长,Apache Parquet 已经成为了一种主流数据存储格式。Apache Parquet 是一种列式存储格式,专为高效的大规模数据处理而设计。它按列而非按行的方式组织数据,这使得 Parquet 在查询时仅读取所需的列,而无需扫描整行数据,即可实现高性能的查询和分析。高效的数据布局使 Parquet 在现代分析生态系统中成为了受欢迎的选择,尤其是在 Apache Spark 工作负载中。
适用于 Apache Spark 的 RAPIDS 加速器基于 cuDF 构建,支持 Parquet 数据格式,可在 GPU 上加速读取和写入数据。对于许多输入数据量达到 TB 级别的大规模 Spark 工作负载而言,高效的 Parquet 扫描对于实现良好的运行时性能至关重要。
本文将讨论如何缓解因较高的寄存器使用率导致的占用限制问题,并分享基准测试结果。
Apache Parquet 数据格式
Parquet 文件格式采用列式存储结构,通过将列线程块组装成行组来实现数据存储。其中元数据不同于数据,可以根据需要拆分到多个文件中(如图 1 所示)。
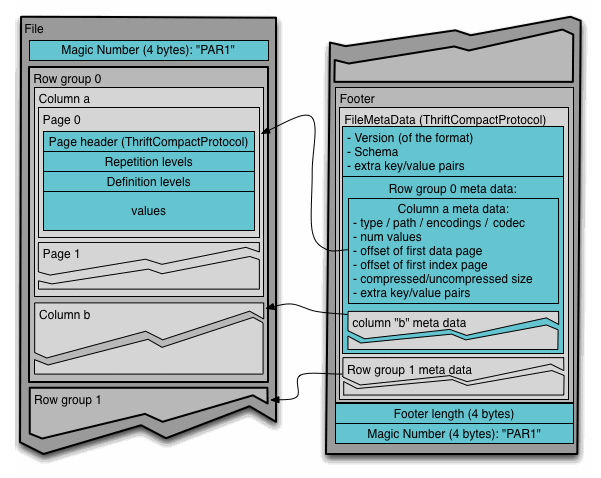
图 1. Parquet 文件格式(来源:文件格式)
Parquet 格式支持多种数据类型。元数据规定了该如何解释这些数据类型,从而能够支持更复杂的逻辑类型表示,比如时间戳、字符串、小数等等。
元数据还可以用于说明更复杂的结构,如嵌套类型和列表。数据可以用多种不同的格式进行编码,例如普通值、字典编码、行程长度编码、位打包(bit-packing)等等。
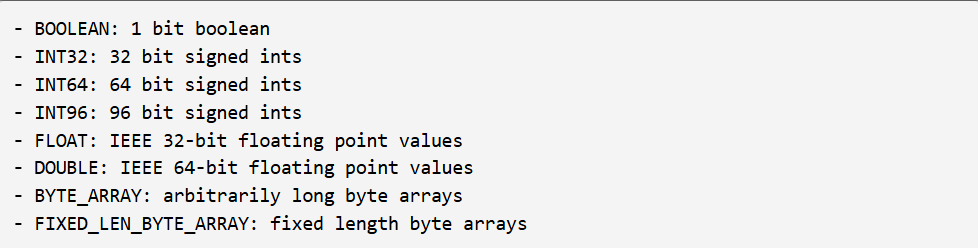
GPU 上 Parquet 的占用限制
在适用于 Apache Spark 的 RAPIDS 加速器之前,Parquet 扫描是通过一个单一 cuDF 内核实现的,它在一组处理代码中支持所有 Parquet 列类型。
使用 Parquet 数据的客户越来越多地在 GPU 上采用 Spark。鉴于 Parquet 扫描对性能有关键影响,人们投入了更多时间来了解其性能特征。以下是几个会影响内核运行效率的常见因素:
流式多处理器(SM):GPU 的主要处理单元,负责执行计算任务。
共享内存:GPU 上集成的内存,按线程块分配,同一线程块中的所有线程都可以访问相同的共享内存。
寄存器:GPU 上集成的快速内存,存储单个线程使用的信息,用于流式多处理器执行的计算操作。
我们在分析 Parquet 扫描时发现,由于遇到寄存器限制,GPU 的总体占用率低于预期。寄存器的使用情况,取决于 CUDA 编译器如何根据内核逻辑和数据管理来生成代码。
对于 Parquet 单内核而言,支持所有列类型的复杂性导致了内核庞大且复杂,其共享内存和寄存器使用率都很高。尽管单一内核可能将代码整合在了一起,但其复杂性限制了可能的优化类型,并在大规模应用时导致了性能受限。
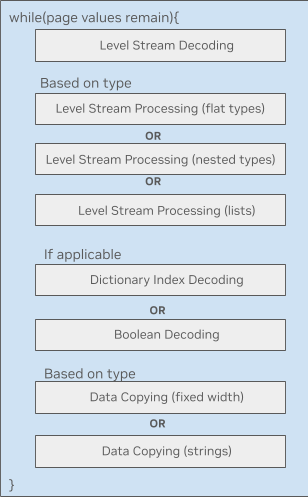
图 2. GPU 上的 Parquet 单内核
图 2 展示了 GPU 上的 Parquet 数据处理循环。每个模块都是大量复杂的内核代码,可能都有各自的共享内存需求。许多线程块依赖于数据类型,这导致加载到内存中的内核变得极为臃肿。
具体而言,其中一个限制在于 Parquet 块在线程束(warp)内的解码方式。线程束在处理自身线程块前,需要按顺序等待先前调度的线程束完成操作。这种机制虽然允许不同线程束并行处理解码过程的不同阶段,但却造成了 GPU 上引入了低效的任务依赖关系,导致效率低下。
转向采用块级解码算法对提升性能至关重要,但由于其增加了数据共享和同步的复杂性,可能会进一步增加寄存器数量并限制占用率。
cuDF 中的 Parquet 微内核
为了缓解因寄存器使用率较高而导致的占用受限问题,最初尝试的方法是为 Parquet 中的预处理列表类型数据创建一个较小的内核。从单内核中分离出一段代码,形成一个独立的内核,结果令人振奋——基准测试的整体结果显示运行时间更快,并且 GPU 跟踪数据也表明占用率有所提高。
随后对不同的列类型也采用了相同的方法。针对各种数据类型的微内核使用 C++ 模板来实现功能复用,这简化了每种类型的代码维护和调试工作。

图 3. GPU 上的 Parquet 微内核方法
Parquet 微内核方法充分利用编译时优化,仅执行处理给定类型所需的代码路径。与包含所有可能代码路径的单一内核不同,该方法可以生成许多单独的微内核,而每个微内核仅包含该路径所需的代码。
这一过程可以通过在编译时使用 if constexpr 来实现。这样一来,使得代码保持自然可读的结构,但不会包含特定数据属性组合(字符串或固定宽度、有列表或无列表等)永远不会执行的代码路径。
以下是一个处理固定宽度类型列的简单示例。可以看到,在新的微内核方法中,大部分不必要的处理步骤都被跳过了。这种数据类型只需要复制数据。
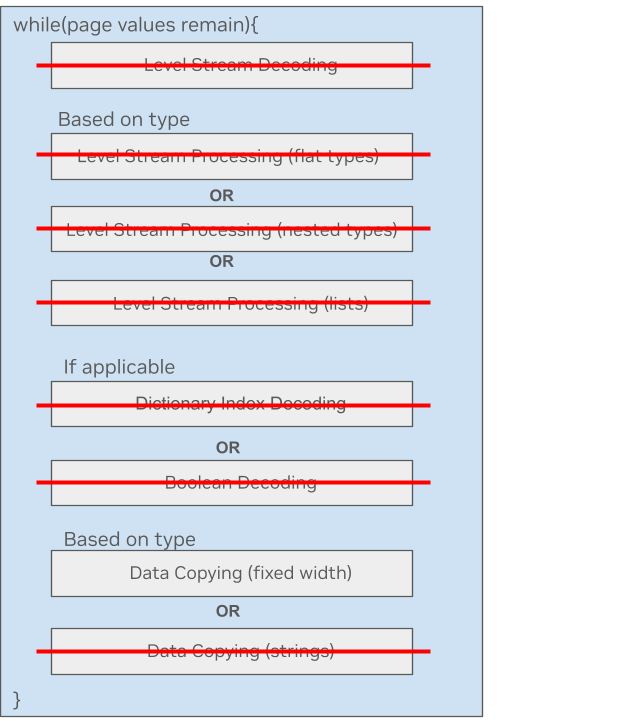
图 4.固定宽度类型的 Parquet 微内核方法
为了解决线程束之间的瓶颈问题,新的微内核使每个步骤都能处理整个线程块,使得线程束可以更高效地独立处理数据。这对于字符串处理尤为重要,它使得 GPU 上包含 128 个线程的完整线程块都能用于复制字符串,而之前的实现方式仅使用一个线程束来复制字符串。
在使用了一块具有 24 GB GPU 显存的 NVIDIA RTX A5000 显卡的本地基准测试中,设备缓冲区中预先加载了 512MB 使用 Snappy 压缩的 Parquet 数据。为了测试分块读取,每次读取 500-KB 的块。测试数据包含以下几种变化:
基数为 0 和 1000
运行长度为 1 和 32
1% 的空值
如果数据有重复,则使用自适应字典编码
图 5 展示了在 GPU 上使用新的微内核方法后,不同 Parquet 列类型在吞吐量方面的提升情况。
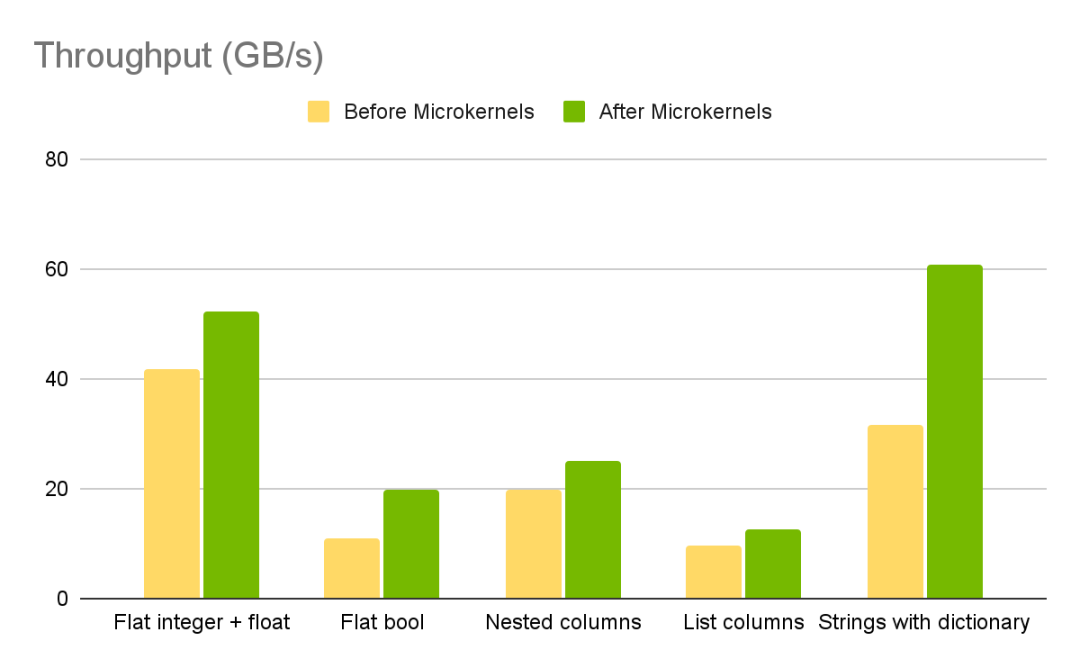
图 5. GPU 上使用 Parquet 微内核方法的吞吐量提升
对列表列分块读取的优化还使 500-KB 读取的吞吐量提高了 117%。
在 GPU 上开始使用 Apache Spark
Parquet 是一种广泛用于大数据处理的关键数据格式。通过使用 cuDF 中经过优化的微内核,GPU 可以加速在 Apache Spark 中扫描 Parquet 数据的进程。
企业可以利用适用于 Apache Spark 的 RAPIDS 加速器,将 Apache Spark 工作负载无缝迁移到 NVIDIA GPU。适用于 Apache Spark 的 RAPIDS 加速器结合了 RAPIDS cuDF 库的强大功能和 Spark 分布式计算框架的规模,利用 GPU 加速处理。通过使用适用于 Apache Spark 的 RAPIDS 加速器插件 JAR 文件启动 Spark,无需更改代码即可在 GPU 上运行现有的 Apache Spark 应用程序。
-
加速器
+关注
关注
2文章
828浏览量
39153 -
数据
+关注
关注
8文章
7259浏览量
92060 -
gpu
+关注
关注
28文章
4956浏览量
131440
原文标题:使用 GPU 加速 Apache Spark 上的 Apache Parquet 扫描
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
RDMA技术在Apache Spark中的应用

《CST Studio Suite 2024 GPU加速计算指南》
如何使用Apache Spark 2.0
Apache Spark 1.6预览版新特性展示
NVIDIA为全球领先的数据分析平台Apache Spark提速
Apache Spark 3.2有哪些新特性
NVIDIA RAPIDS加速器可将工作分配集群中各节点
利用Apache Spark和RAPIDS Apache加速Spark实践
使用Apache Spark和NVIDIA GPU加速深度学习
NVIDIA TensorRT与Apache Beam SDK的集成
NVIDIA加速的Apache Spark助力企业节省大量成本






 工商网监
工商网监
评论